LabelEncoder
10.09.2016
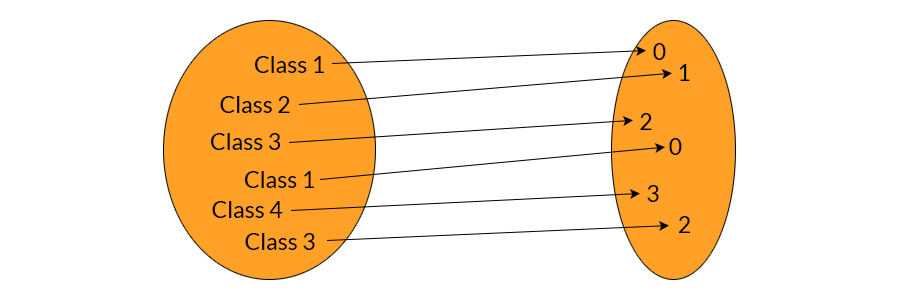
Czasami, przetwarzając zbiór danych, mamy do czynienia ze zmiennymi, które są typu tekstowego i przyporządkowują obserwację statystyczną do jakiejś kategorii. Przykładowo, mamy do czynienia z uczniami pewnej szkoły, którzy chodzą do różnych klas (1A, 1B, 1C, 2A, 2B, 2C itd.). Chcemy takie zmienne zamienić na liczby w celu ich dalszego przetwarzania przez jakiś wybrany algorytm np. random forest. Można do tego użyć klasy LabelEncoder z biblioteki scikit-learn.
#!/usr/bin/python2.7
from __future__ import print_function
import numpy as np
from sklearn.preprocessing import LabelEncoder
X = np.array(['1A', '1B', '1C', '2A', '1A', '3C'])
lbl_enc = LabelEncoder()
lbl_enc.fit(X)
X_cat = lbl_enc.transform(X)
print(X_cat)
Na wyjściu otrzymujemy:
[0 1 2 3 0 4]
Kategorie: Przepisy